Извлечь данные

Описание
Блок осуществляет извлечение данных на странице браузера. Требуется указать извлекаемые атрибутов элемента.
Описание параметров
Блок имеет несколько основных параметров:
- Тег элемента - тег веб-элемента на html странице браузера.
Тип данных:
str (Строка)Пример:
h1 - Атрибут элемента - словарь атрибутов, из которых необходимо извлечь данные.
Тип данных:
dict (Словарь)Пример:
{class: "header-class"} - Сессия браузера - экземпляр запущенного браузера, управляемый через Selenium WebDriver или pyDoll.
В переменной хранится ссылка на этот экземпляр, через которую можно управлять браузером;
Клик по символу
Тип данных:
var (Переменная)Пример:
web_actions раскрывающегося списка открывает следующее
меню выбора переменной:
раскрывающегося списка открывает следующее
меню выбора переменной:
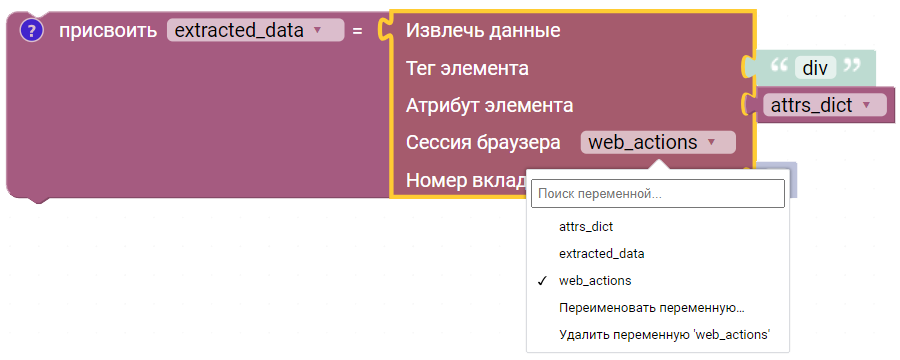
- Номер вкладки по порядку - порядковый номер вкладки по порядку, в которой необходимо выполнить действие.
Тип данных:
int (Число)Пример:
0
При нажатии на кнопку открывается Мастер UI для веб-автоматизации
открывается Мастер UI для веб-автоматизации
открывается Мастер UI для веб-автоматизации Мастер UI для веб-автоматизации Редактор XPATH - встроенный инструмент Puzzle RPA, который упрощает работу с языком запросов XPATH. Подробнее...
Пример использования
В данном примере происходит проверка на наличие веб-элемента на html странице:

Алгоритм ожидания веб-элемента:
- Открывается html страница из папки resources проекта;
- Извлекаются данные веб-элементу по тегу
h1и классуheader-class; - Уведомление о результате извлечения данных;
-
Проект процесса и материалы для его выполнения
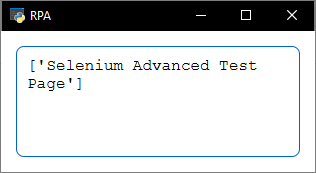
Результат
Вывод результата на экран: