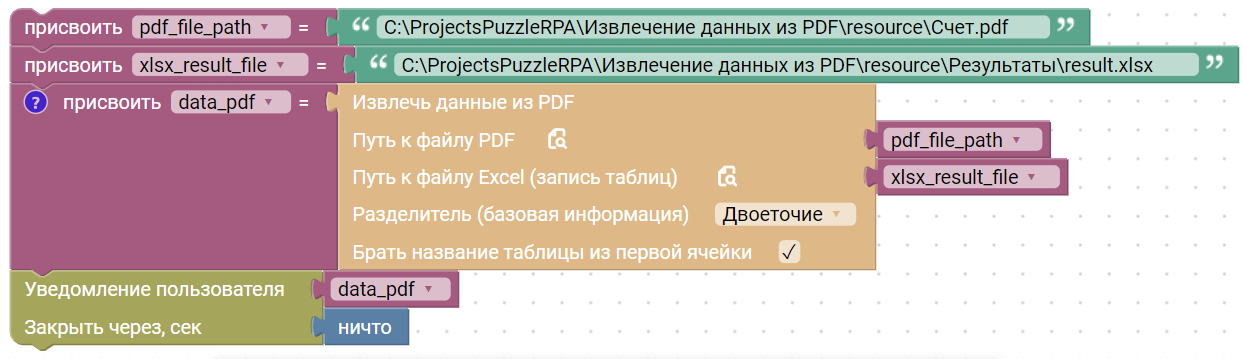
Извлечь данные из PDF

Описание
Блок извлекает из PDF структурированные данные: базовую текстовую информацию по разделителю и таблицы. Таблицы сохраняются в Excel-файл (каждая на отдельный лист), имена листов соответствуют именам таблиц.
Описание параметров
Блок имеет несколько параметров:
- Путь к файлу PDF — исходный документ.
Тип данных:
str (Строка)Пример:
C:\Users\User\Desktop\test.pdf - Путь к файлу Excel (запись таблиц) — куда сохранить извлечённые таблицы.
Тип данных:
str (Строка)Пример:
C:\Users\User\Desktop\test.xlsx - Разделитель (базовая информация) — символ для разбора текстовых пар «реквизит — значение»: двоеточие или тире.
Тип данных:
str (Строка)Пример:
: - Брать название таблицы из первой ячейки — использовать первую ячейку таблицы как имя.
Тип данных:
checkbox (Чекбокс)Пример:
✔
Возвращаемое значение
Массив словарей:
- словарь с базовой информацией: ключ — реквизит, значение — извлечённое значение;
- словари с табличными данными: ключ — имя таблицы, значение — таблица данных (датафрейм).
Если включён чекбокс Брать название таблицы из первой ячейки, имя таблицы берётся из первой ячейки; при совпадении имён они индексируются.
Тип данных: list (Список)
Пример: [{"Итого к оплате": "10 000.00 руб"}, {"Товары (работы, услуги)": "DataFrame"}]
Пример использования
Блок извлекает таблицы из счёта на оплату и пары «ключ: значение» в базовой части документа.
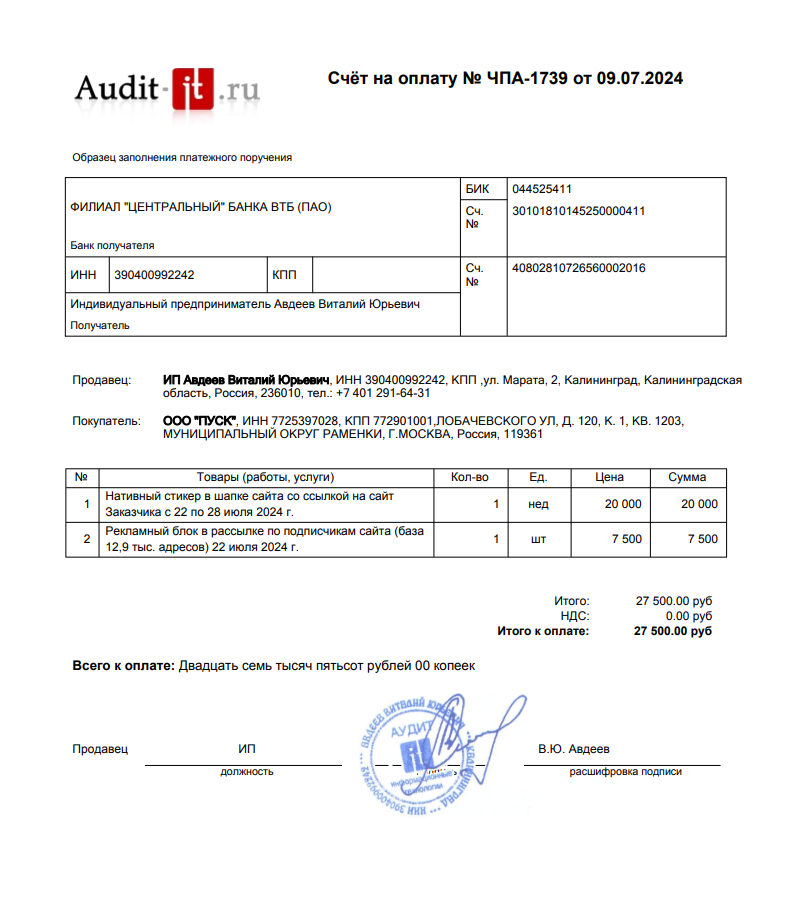
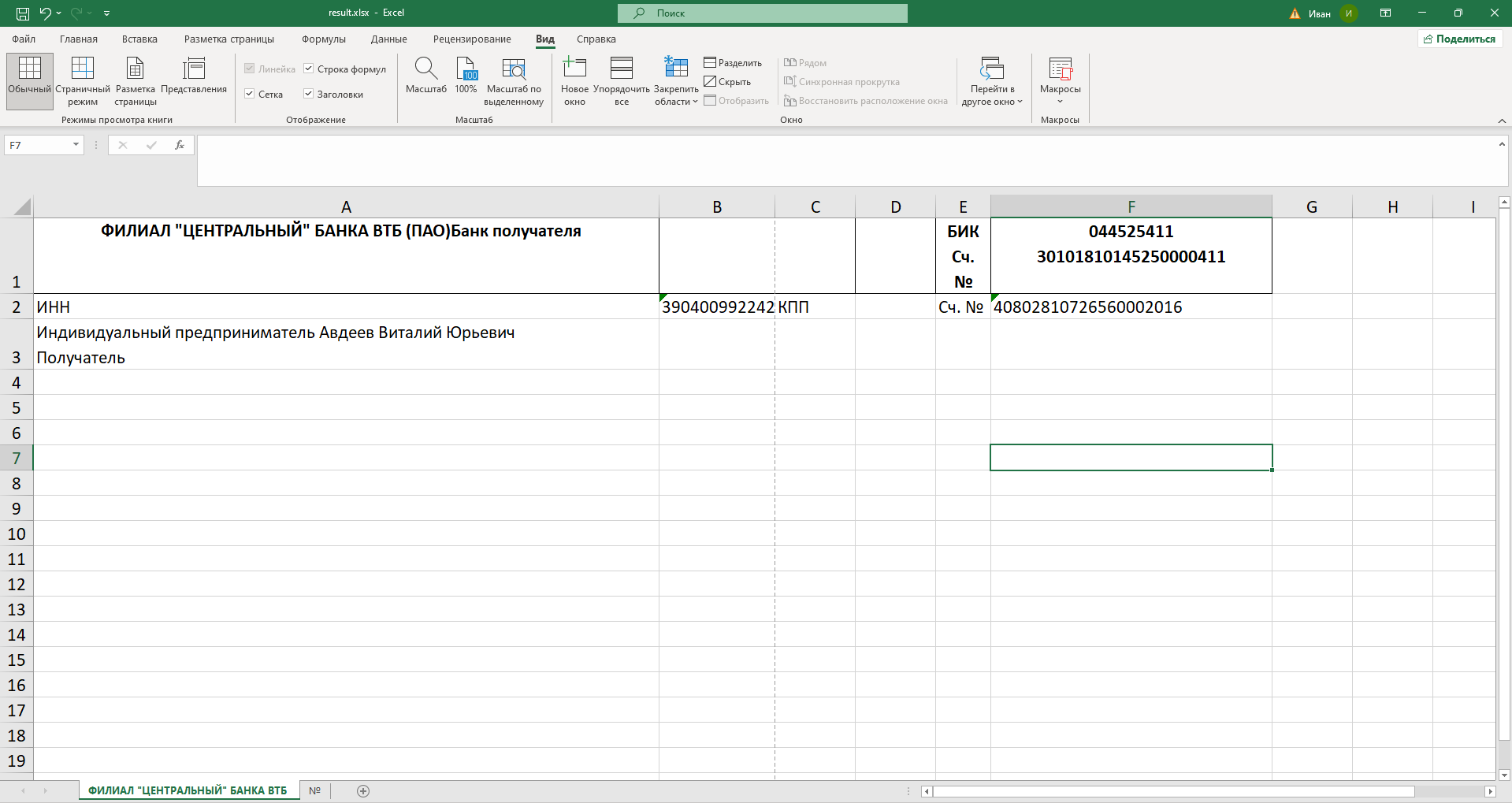
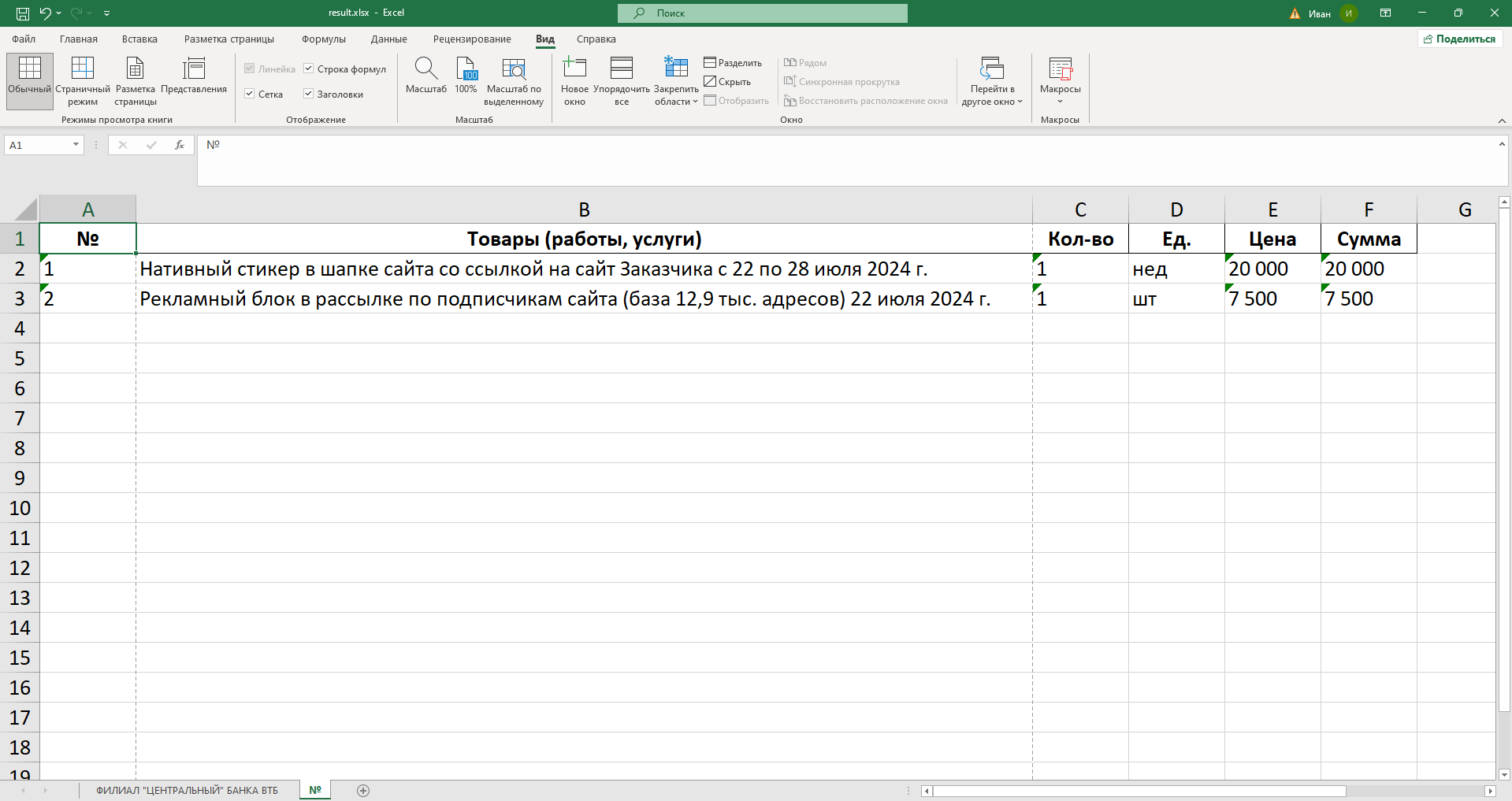
Результат выводится на экран и каждая таблица записывается в отдельный лист Excel-файла.
Результат