Распознать области

Описание
Блок распознает текстовые области документа и/или данные по ключевым словам.
Описание параметров
Блок имеет ряд параметров:
-
Файл документа — путь к входному файлу;
Тип данных:
str (Строка)Пример:
C:\docs\invoice.jpg -
Режим распознавания — способ извлечения данных (
области для распознаванияилиключевые слова);Тип данных:
str (Строка)Пример:
ключевые слова -
Параметры поиска (области для распознавания) — список областей для извлечения;
Тип данных:
dict (Словарь)Пример:
{1: [(515, 119), (971, 285)], 2: [(1170, 98), (1636, 172)]} -
Параметры поиска (ключевые слова) — список ключевых слов для извлечения;
Тип данных:
list (Список)Пример:
[["Поставщик:", "Покупатель:"], "Счет на оплату"] -
Языковая модель — язык распознавания:
- RUS - блок распознаёт и обрабатывает текст только на русском языке;
- ENG - блок распознаёт и обрабатывает текст только на английском языке.;
- RUS+ENG - блок работает в многоязычном режиме: автоматически определяет язык каждого фрагмента текста (русский или английский) и применяет соответствующую языковую модель для его обработки.
-
Путь к файлу результата — путь к файлу сохранения результата;
Тип данных:
str (Строка)Пример:
C:\docs\ocr_result.json -
OAuth-токен Yandex — токен доступа к Yandex Vision;
Тип данных:
str (Строка)Пример:
y0_AQAAAA... -
Идентификатор каталога Yandex — ID каталога в Yandex Cloud;
Тип данных:
str (Строка)Пример:
b1gxxxxxxxxxxxxx
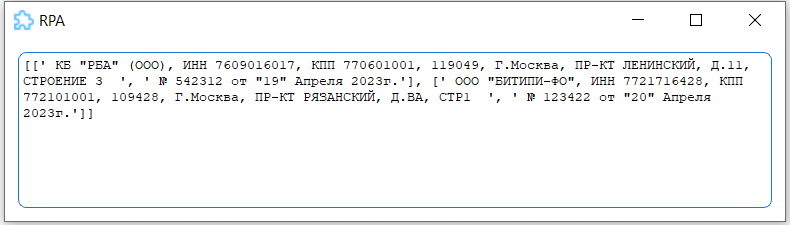
Пример использования
В данном примере распознаются данные из счетов на оплату по ключевым словам.
- Определяются пути ко всем файлам для обработки.
- Создается список для накопления результатов.
- В цикле выполняется распознавание по ключам
Поставщик:иПокупатель:. - Результаты добавляются в итоговый список и выводятся пользователю.
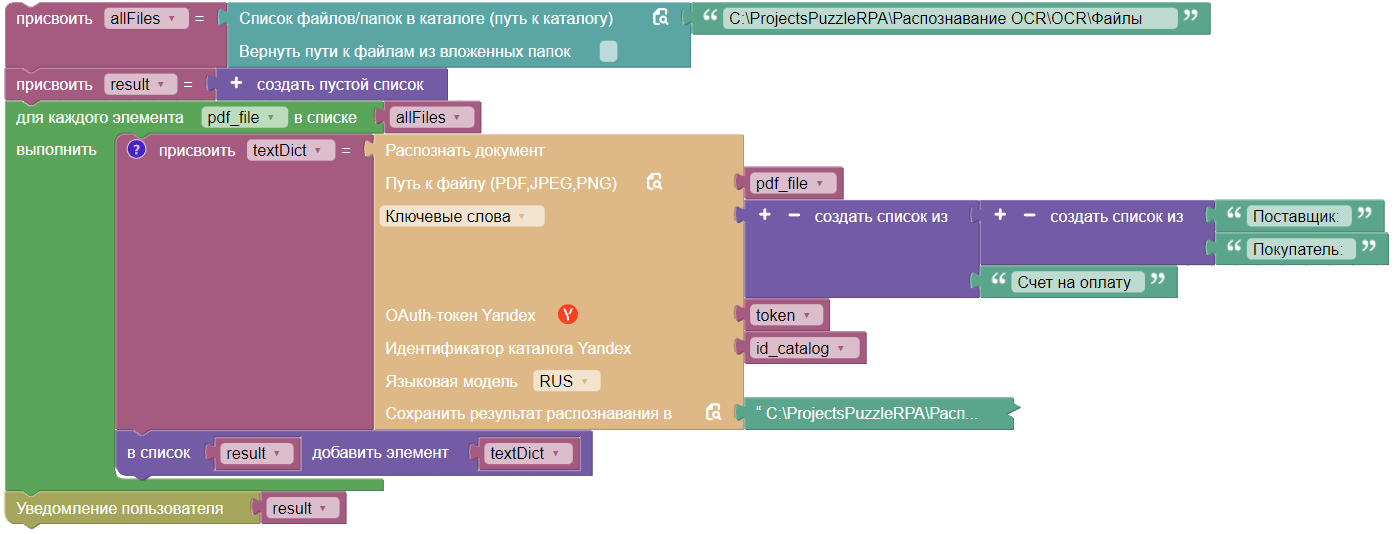
Результат
Вывод результата распознавания: