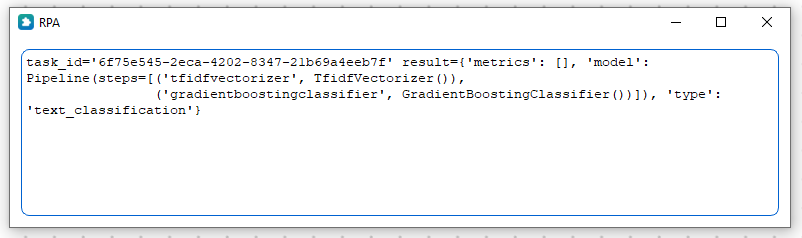
Обучить классификационную модель

Описание
Блок позволяет обучить классификационную модель.
Для этого необходимо выбрать один из алгоритмов из выпадающего списка, а также указать путь к файлу с данными для обучения, используемые колонки в форме списка, название целевой колонки.
При обучении используются метрики:
- Точность - метрика оценки качества модели машинного обучения, которая измеряет долю правильных предсказаний, сделанных моделью, относительно общего числа предсказаний. Она вычисляется как отношение числа правильно классифицированных объектов ко всем объектам в тестовой выборке;
- Достоверность - метрика оценки качества модели машинного обучения, которая вычисляется как среднее арифметическое полноты для каждого класса. Полнота для каждого класса определяется как отношение числа правильно предсказанных положительных примеров к общему числу реальных положительных примеров в этом классе;
- Средняя точность (f1_macro) - метрика оценки качества модели машинного обучения, которая вычисляется как среднее гармоническое F1-меры для каждого класса. F1-мера для каждого класса рассчитывается как среднее гармоническое точности и полноты;
- Общая полнота по всем классам (recall_micro) - — это метрика оценки качества модели машинного обучения, которая вычисляется как общая полнота по всем классам путем суммирования числителей и знаменателей для всех классов и последующего вычисления отношения.
Блок имеет 2 выпадающих меню. Клик по символу раскрывающегося списка открывает следующее меню:
- Выполнить обучение:
- Локально;
- На удаленном сервере;
- Алгоритм:
- Auto;
- RandomForestClassifier - Представляет собой ансамбль деревьев решений, используемый для задач классификации. Сначала формируется случайная подвыборка данных из обучающего набора с заменой (bootstrap sample). На основе этой подвыборки строится решающее дерево, при этом на каждом узле выбирается лучший разделитель из случайного подмножества признаков;
- GradientBoostingClassifier - Метод машинного обучения, основанный на идее построения ансамбля слабых моделей, обучаемых последовательно с целью минимизации функции потерь с использованием градиентного спуска. В процессе работы алгоритма каждая новая модель настраивается на остатки предыдущих моделей, улучшая предсказательную способность ансамбля на каждой итерации;
- KNeighborsClassifier - Метод машинного обучения, используемый для задач классификации на основе ближайших соседей. Основная идея заключается в том, что объекты с похожими признаковыми описаниями склонны принадлежать к одному классу;
- SGDClassifier - Метод машинного обучения, основанный на нахождении оптимального коэффициента линейных классификаторов, обновляя параметры модели с помощью градиента функции потерь. Этот метод особенно полезен при работе с большими наборами данных, поскольку обновляет параметры модели на небольших подвыборках, избегая необходимости обрабатывать весь набор данных и экономя вычислительные ресурсы;
- SVC - Метод, основанный на концепции Support Vector Machines (SVM), которая строит гиперплоскость в пространстве признаков, разделяющую классы с максимальным зазором между ними;
- MLPClassifier - Многослойный перцептрон.
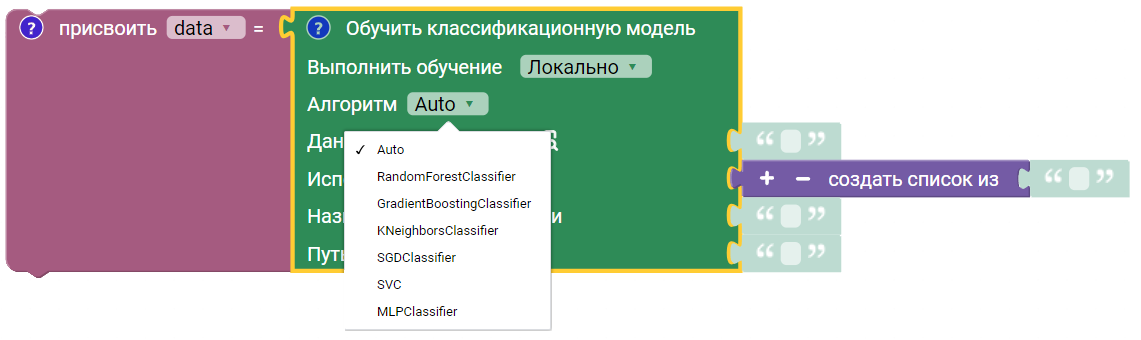
Пример использования
В данном примере на основе xlsx-файла осуществляется обучение классификационной модели. Результат сохраняется в файл classifier_model.

В данном примере на основе xlsx-файла осуществляется обучение классификационной модели на удаленном сервере. ID полученной модели сохраняется в файл classifier_model_id.
- Параметр “Сохранить идентификатор модели в” не является обязательным.

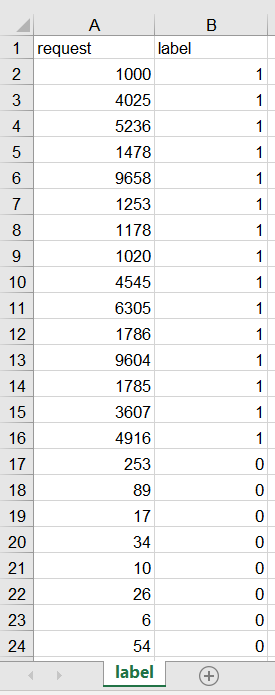
Данные в файле (числа до 1000 имеют метку 1, а после 1000 имеют метку 1):
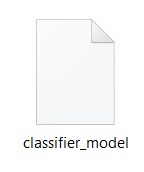
Результат
Файл с обученной моделью на диске:
Информация о созданной модели на сервере: