Обучить модель кластеризации

Описание
Блок позволяет обучить модель кластеризации.
Для этого необходимо выбрать один из алгоритмов из выпадающего списка, а также указать путь к файлу с данными для обучения, используемую колонку, начальное количество кластеров, максимальное количество кластеров, оптимальный подбор для количества кластеров и путь для сохранения модели.
При обучении используются метрики:
- Коэффициент сходства объектов внутри кластера (silhouette_score) - используется для оценки качества кластеризации в задачах машинного обучения. Она помогает понять, насколько хорошо объекты внутри одного кластера схожи между собой, и насколько они отличаются от объектов в других кластерах.
Блок имеет 2 выпадающих меню. Клик по символу раскрывающегося списка открывает следующее меню:
- Выполнить обучение:
- Локально;
- На удаленном сервере;
- Алгоритм:
- KMeans - Метод кластеризации, который разбивает набор данных на заранее определенное количество кластеров, минимизируя сумму квадратов расстояний между точками данных и центрами их соответствующих кластеров. Он применяется тогда, когда требуется разделить данные на группы на основе сходства между ними, и известно заранее количество кластеров, которое необходимо образовать. KMeans эффективен при достаточно больших и четко определенных кластерах, но может давать неоптимальные результаты при неоднородных или сложных структурах данных.
Пример использования
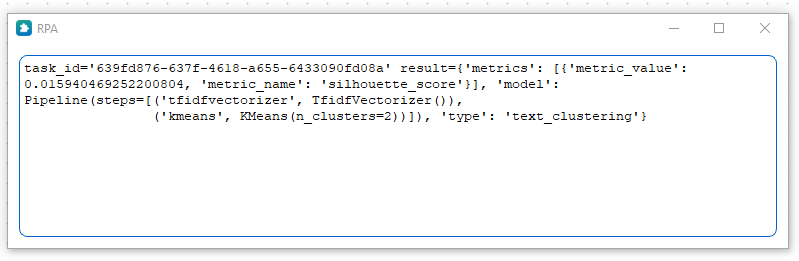
В данном примере на основе xlsx-файла осуществляется обучение модели кластеризации. Результат сохраняется в файл clustering_model.
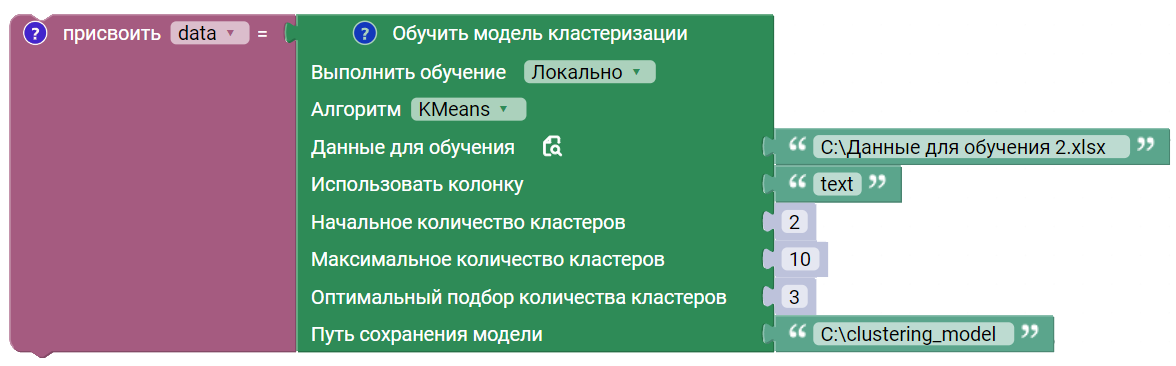
В данном примере на основе xlsx-файла осуществляется обучение модели кластеризации на удаленном сервере. ID полученной модели сохраняется в файл clustering_model_id.
- Параметр “Сохранить идентификатор модели в” не является обязательным.

Данные в файле:

Результат
Файл с обученной моделью на диске:
Информация о созданной модели на сервере: