Обучить классификационную модель
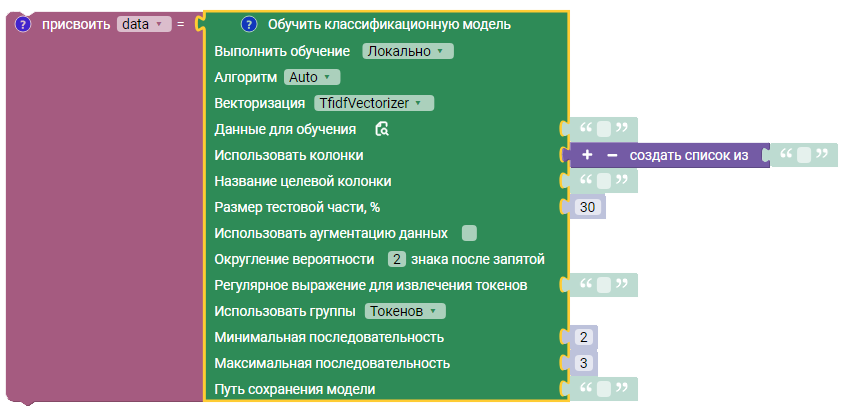
Описание
Блок позволяет обучить классификационную модель, которая предсказывает категорию объекта по заранее заданным параметрам.
Параметры модели
Блок имеет несколько выпадающих списков:
- Выполнить обучение:
- Локально - Обучение модели выполняется на компьютере пользователя;
- Удаленно - Обучение модели выполняется на удаленном компьютере (требуется установка дополнительного серверного компонента на используемый сервер).
- Алгоритм:
- Auto - Автоматический выбор на основе метрик;
- RandomForestClassifier - Представляет собой ансамбль деревьев решений, используемый для задач классификации. Сначала формируется случайная подвыборка данных из обучающего набора с заменой (bootstrap sample). На основе этой подвыборки строится решающее дерево, при этом на каждом узле выбирается лучший разделитель из случайного подмножества признаков;
- GradientBoostingClassifier - Метод машинного обучения, основанный на идее построения ансамбля слабых моделей, обучаемых последовательно с целью минимизации функции потерь с использованием градиентного спуска. В процессе работы алгоритма каждая новая модель настраивается на остатки предыдущих моделей, улучшая предсказательную способность ансамбля на каждой итерации;
- KNeighborsClassifier - Метод машинного обучения, используемый для задач классификации на основе ближайших соседей. Основная идея заключается в том, что объекты с похожими признаковыми описаниями склонны принадлежать к одному классу;
- SGDClassifier - Метод машинного обучения, основанный на нахождении оптимального коэффициента линейных классификаторов, обновляя параметры модели с помощью градиента функции потерь. Этот метод особенно полезен при работе с большими наборами данных, поскольку обновляет параметры модели на небольших подвыборках, избегая необходимости обрабатывать весь набор данных и экономя вычислительные ресурсы;
- SVC - Метод, основанный на концепции Support Vector Machines (SVM), которая строит гиперплоскость в пространстве признаков, разделяющую классы с максимальным зазором между ними;
- MLPClassifier - Многослойный перцептрон.
- Векторизация:
- TfidfVectorizer - преобразует текстовые документы в числовые векторы, основанные на методе TF-IDF (Term Frequency-Inverse Document Frequency). Он вычисляет важность каждого слова в документе относительно всего корпуса, учитывая как частоту его появления (TF), так и редкость в других документах (IDF);
- Word2Vec - позволяет преобразовать слова из корпуса текстов в векторы чисел таким образом, что слова с похожими семантическими значениями имеют близкие векторные представления в многомерном пространстве.
Параметры обучаемой модели
Блок имеет следующие параметры для обучаемой модели:
- Размер тестовой части (%) - Процент выборки тестовых данных из исходного массива данных;
- Использовать аугментацию данных - Чекбокс увеличения объема обучающего набора данных путем применения различных трансформаций к исходным данным:
- Количество уникальных аугментированных копий - Количество уникальных аугментированных копий для каждой строки;
- Доля случайных замен (%) - Доля случайных замен в тексте;
- Вероятность заменить русскую букву на похожую английскую (%) - Вероятность заменить русскую букву на похожую английскую в тексте;
- Округление веротности (количество знаков после запятой) - Количество символов для округления вероятности вхождения в каждый класс для выявления неопределенности в результате;
- Регулярное выражение для извлечения токенов (регулярное выражение) - Параметр позволяет определить, как именно будут извлекаться токены (слова или фразы) из текстовых данных (пример:
(?u)\\b\\w\\w+\\b- все слова в тексте, которые содержат два или более символов с учетом границ слов, используя Unicode для поддержки различных языков); - Использовать группы Токенов/Слов/Символов (при использовании TfidfVectorizer) - Определяет, как будет производиться анализ текстовых данных для извлечения признаков;
- Минимальная последовательность - определяет минимальное количество n-грамм, которые будут извлечены из текстовых данных;
- Максимальная последовательность - определяет максимальное количество n-грамм, которые будут извлечены из текстовых данных.
Параметры для алгоритма RandomForestClassifier:
- Минимальное количество листьев - определяет минимальное количество образцов (или экземпляров), которые должны быть в листовом узле дерева;
- Длина дерева - определяет максимальную глубину дерева решений;
- Учет дисбаланса - позволяет учитывать несбалансированные классы в классификации.
Выбор данных для обучения
Для обучения модели необходимо указать:
- Данные для обучения - Данные для обучения модели;
- Использовать колонки - Список колонок с данными для обучения;
- Название целевой колонки - Название колонки, содержащей категории, соответствующие обучающим данным.
Выбор места обучения
Для локального обучения:
- Путь сохранения модели - Путь файла с моделью, которая будет сохранена после обучения.
Для обучения на сервере:
- Адрес базы данных SQL - Адрес базы данных, в которой хранятся обученные модели;
- Адрес удаленного сервера - Адрес удаленного сервера для обучения;
- Сохранить результат обучения в - Путь до файла JSON, в который будет сохранена информация о обученной модели.
Используемые метрики
При обучении используются метрики:
- Точность (f1_macro) - метрика оценки качества модели машинного обучения, которая вычисляется как среднее гармоническое F1-меры для каждого класса. F1-мера для каждого класса рассчитывается как среднее гармоническое точности и полноты.
- Аккуратность (accuracy) - метрика оценки качества модели машинного обучения, которая измеряет долю правильных предсказаний, сделанных моделью, относительно общего числа предсказаний. Она вычисляется как отношение числа правильно классифицированных объектов ко всем объектам в тестовой выборке.
- Средняя полнота по всем классам (recall_macro) - метрика оценки качества модели машинного обучения, которая вычисляется как среднее арифметическое полноты для каждого класса. Полнота для каждого класса определяется как отношение числа правильно предсказанных положительных примеров к общему числу реальных положительных примеров в этом классе.
- Общая полнота по всем классам (recall_micro) - это метрика оценки качества модели машинного обучения, которая вычисляется как общая полнота по всем классам путем суммирования числителей и знаменателей для всех классов и последующего вычисления отношения.
- Матрица ошибок (confusion_matrix) - это инструмент, используемый для оценки качества работы классификаторов в машинном обучении. Она позволяет визуализировать производительность модели, показывая, как часто предсказания совпадают с реальными значениями.
- TP (True Positives): количество истинно положительных результатов (правильно предсказанные положительные классы);
- TN (True Negatives): количество истинно отрицательных результатов (правильно предсказанные отрицательные классы);
- FP (False Positives): количество ложно положительных результатов (неправильно предсказанные положительные классы);
- FN (False Negatives): количество ложно отрицательных результатов (неправильно предсказанные отрицательные классы).
Информация о модели
Блок возвращает список, содержащий два DataFrame.
- Информация о созданной модели:
- task_id (*При обучении на сервере) - ID модели на сервере;
- model - Информация о модели: Алгоритм и выбранные параметры для него;
- metric_name и metric_value - Метрики и их значения;
- Информация о нагрузке на систему - Нагрузка на центральный процессор, загрузка оперативной памяти, время обучения.
- Результат использования модели на тестовых данных:
- Тестовые данные;
- Результат классификации;
- Вероятности вхождения в каждый существующий класс.
Пример использования
В данном примере блок выполняет обучение модели классификации.
-
Формируется обучающая выборка для модели классификации, включающая несколько классов данных;

-
Выполняется обучение:
В данном примере блок выполняет локальное обучение модели классификации:
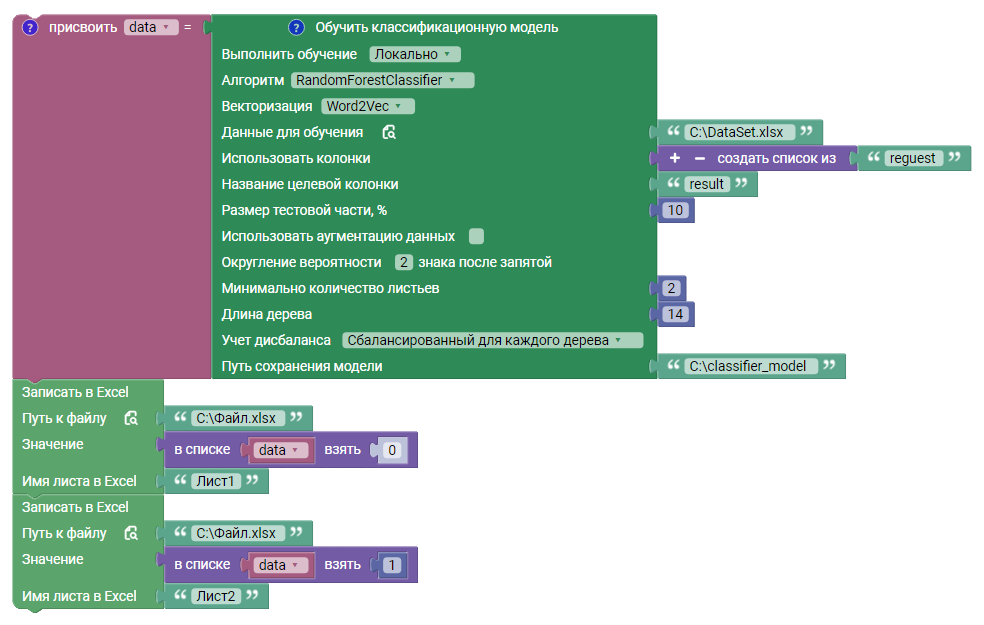
Созданная модель сохраняется в файл classifier_model, путь до которого указывается в поле “Путь сохранения модели”.
В данном примере блок выполняет обучение модели классификации на сервере:
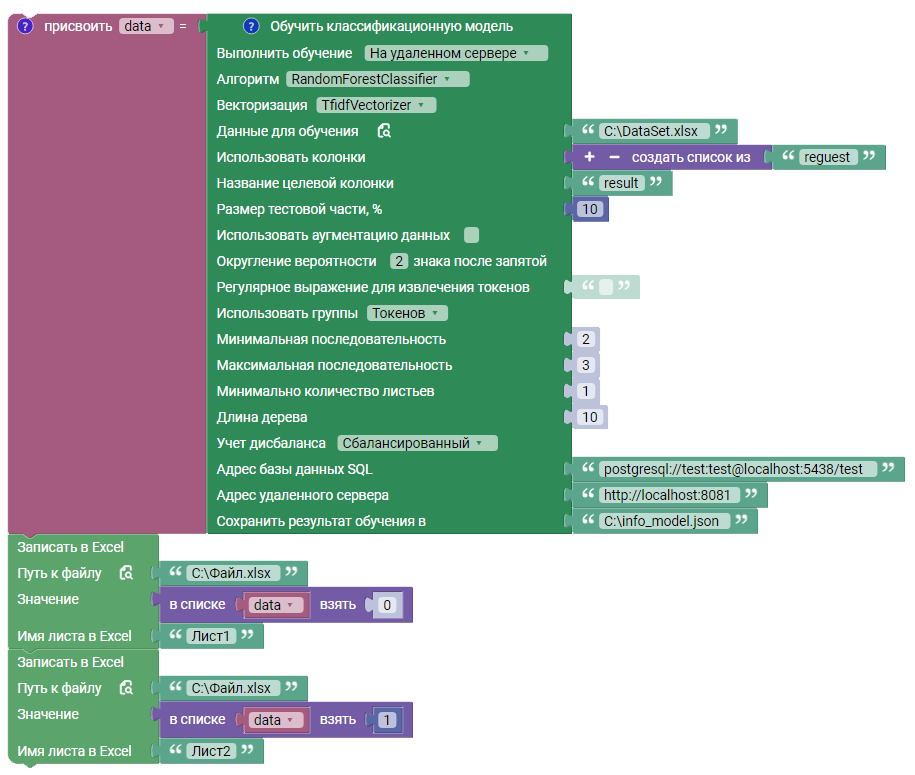
В поле “Сохранить результат обучение в” указывается JSON файл “info_model.json”, в который сохраняется информация о созданной модели на сервере.
-
Информация о модели сохраняется в Excel - Файл:
Лист1 - Информация о созданной модели:
- task_id (*При обучении на сервере) - ID модели на сервере;
- model - Информация о модели: Алгоритм и выбранные параметры для него;
- metric_name и metric_value - Метрики и их значения;
- Информация о нагрузке на систему - Нагрузка на центральный процессор, загрузка оперативной памяти, время обучения.
Лист2 - Результат использования модели на тестовых данных:
- Тестовые данные;
- Результат классификации;
- Вероятности вхождения в каждый существующий класс.
Результат
Лист1 - Информация о созданной модели, метрики и данные о нагрузке на систему:

Лист2 - Результат использования модели на тестовых данных:

Сохраненный файл с моделью:
Лист1 - Информация о созданной модели, метрики и данные о нагрузке на систему:

Лист2 - Результат использования модели на тестовых данных:
Содержимое файла info_model.json
{ "task_id": "f19e3291-67f5-4b52-8a56-050856ba685c", "type": "text_classification", "model": "RandomForestClassifier(class_weight='balanced', max_depth=10), TfidfVectorizer(ngram_range=(2, 3))", "metrics": [ { "metric_value": 0.82857142857142855, "metric_name": "Точность" }, { "metric_value": 0.75, "metric_name": "Аккуратность" }, { "metric_value": 0.5, "metric_name": "Средняя полнота по всем классам" }, { "metric_value": 0.75, "metric_name": "Общая полнота по всем классам" }, { "metric_value": "{'TP': 0, 'TN': 3, 'FP': 0, 'FN': 1}", "metric_name": "Матрица ошибок" } ], "cpu_usage": { "cpu_percent": 0.6297376093294461, "ram_MB": 467.89545941144314 }, "time": 0.1696772575378418}