Обучить модель кластеризации

Описание
Блок позволяет обучить модель кластеризации, которая позволяет группировать объекты в однородные кластеры на основе их характеристик.
Параметры модели
Блок имеет несколько выпадающих списков:
- Выполнить обучение:
- Локально - Обучение модели выполняется на компьютере пользователя;
- Удаленно - Обучение модели выполняется на удаленном компьютере (требуется установка дополнительного серверного компонента на используемый сервер).
- Алгоритм:
- KMeans - Метод кластеризации, который разбивает набор данных на заранее определенное количество кластеров, минимизируя сумму квадратов расстояний между точками данных и центрами их соответствующих кластеров. Он применяется тогда, когда требуется разделить данные на группы на основе сходства между ними, и известно заранее количество кластеров, которое необходимо образовать. KMeans эффективен при достаточно больших и четко определенных кластерах, но может давать неоптимальные результаты при неоднородных или сложных структурах данных.
- Векторизация:
- TfidfVectorizer - преобразует текстовые документы в числовые векторы, основанные на методе TF-IDF (Term Frequency-Inverse Document Frequency). Он вычисляет важность каждого слова в документе относительно всего корпуса, учитывая как частоту его появления (TF), так и редкость в других документах (IDF);
- Word2Vec - позволяет преобразовать слова из корпуса текстов в векторы чисел таким образом, что слова с похожими семантическими значениями имеют близкие векторные представления в многомерном пространстве.
Параметры обучаемой модели
Блок имеет следующие параметры для обучаемой модели:
- Размер тестовой части (%) - Процент выборки тестовых данных из исходного массива данных;
- Начальное количество кластеров - Минимальное число созданных кластеров;
- Максимальное количество кластеров - Максимальное число созданных кластеров;
- Оптимальный подбор количества кластеров - число созданных кластеров;
- Регулярное выражение для извлечения токенов (регулярное выражение) - Параметр позволяет определить, как именно будут извлекаться токены (слова или фразы) из текстовых данных (пример:
(?u)\\b\\w\\w+\\b- все слова в тексте, которые содержат два или более символов с учетом границ слов, используя Unicode для поддержки различных языков); - Использовать группы Токенов/Слов/Символов (при использовании TfidfVectorizer) - Определяет, как будет производиться анализ текстовых данных для извлечения признаков;
- Минимальная последовательность - определяет минимальное количество n-грамм, которые будут извлечены из текстовых данных;
- Максимальная последовательность - определяет максимальное количество n-грамм, которые будут извлечены из текстовых данных.
Выбор данных для обучения
Для обучения модели необходимо указать:
- Данные для обучения - Данные для обучения модели;
- Использовать колонки - Список колонок с данными для обучения.
Выбор места обучения
Для локального обучения:
- Путь сохранения модели - Путь файла с моделью, которая будет сохранена после обучения.
Для обучения на сервере:
- Адрес базы данных SQL - Адрес базы данных, в которой хранятся обученные модели;
- Адрес удаленного сервера - Адрес удаленного сервера для обучения;
- Сохранить результат обучения в - Путь до файла JSON, в который будет сохранена информация о обученной модели.
Используемые метрики
При обучении используются метрики:
- Коэффициент сходства объектов внутри кластера (silhouette_score) - используется для оценки качества кластеризации в задачах машинного обучения. Она помогает понять, насколько хорошо объекты внутри одного кластера схожи между собой, и насколько они отличаются от объектов в других кластерах.
Информация о модели
Блок возвращает список, содержащий два DataFrame.
- Информация о созданной модели:
- task_id (*При обучении на сервере) - ID модели на сервере;
- model - Информация о модели: Алгоритм и выбранные параметры для него;
- metric_name и metric_value - Метрики и их значения;
- Информация о нагрузке на систему - Нагрузка на центральный процессор, загрузка оперативной памяти, время обучения.
- Результат использования модели на тестовых данных:
- Тестовые данные;
- Результат кластеризации.
Пример использования
В данном примере блок выполняет обучение модели кластеризации.
-
Формируется обучающая выборка для модели кластеризации, включающая несколько классов данных;

-
Выполняется обучение:
В данном примере блок выполняет локальное обучение модели кластеризации:
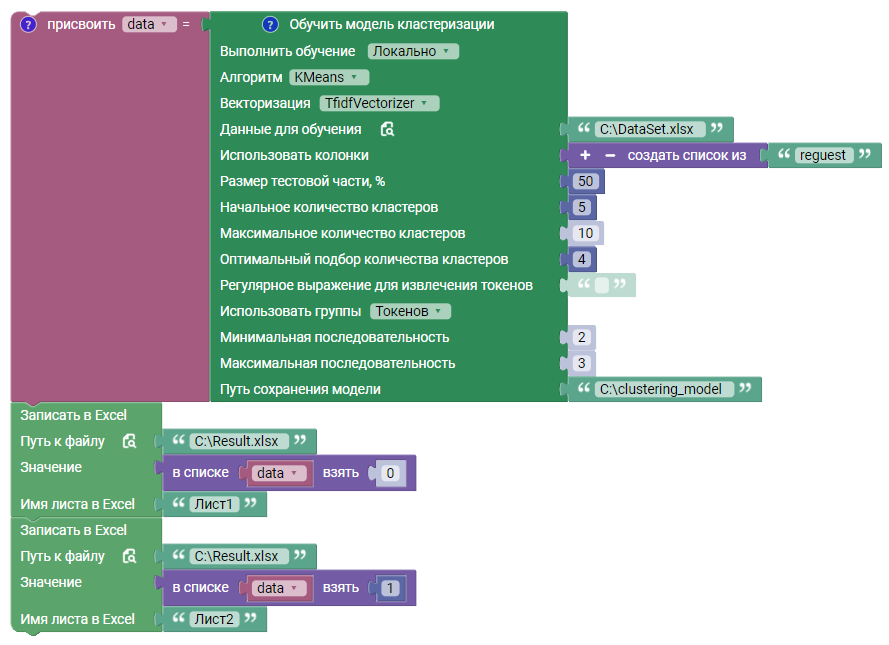
Созданная модель сохраняется в файл clustering_model, путь до которого указывается в поле “Путь сохранения модели”.
В данном примере блок выполняет обучение модели кластеризации на сервере:
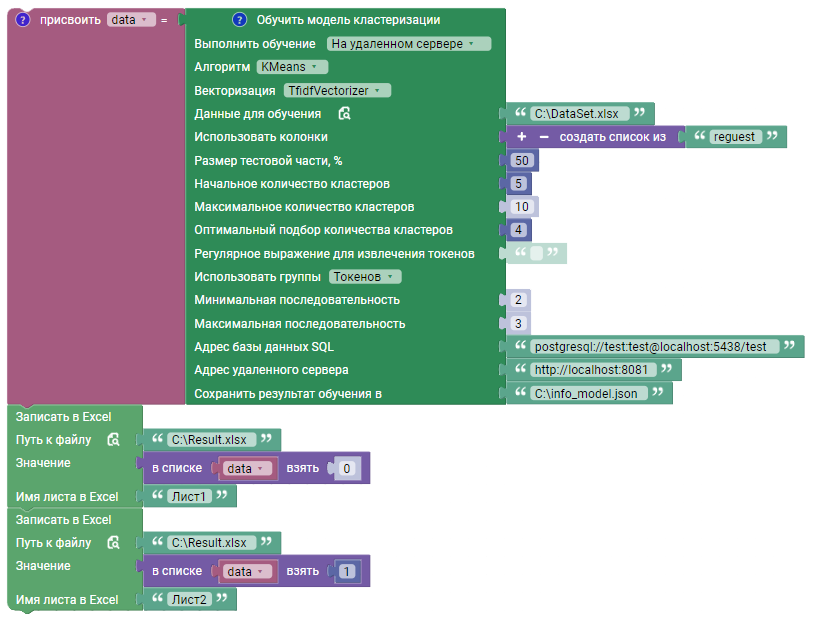
В поле “Сохранить результат обучение в” указывается JSON файл “info_model.json”, в который сохраняется информация о созданной модели на сервере.
-
Информация о модели сохраняется в Excel - Файл:
Лист1 - Информация о созданной модели:
- task_id (*При обучении на сервере) - ID модели на сервере;
- model - Информация о модели: Алгоритм и выбранные параметры для него;
- metric_name и metric_value - Метрики и их значения;
- Информация о нагрузке на систему - Нагрузка на центральный процессор, загрузка оперативной памяти, время обучения.
Лист2 - Результат использования модели на тестовых данных:
- Тестовые данные;
- Результат кластеризации.
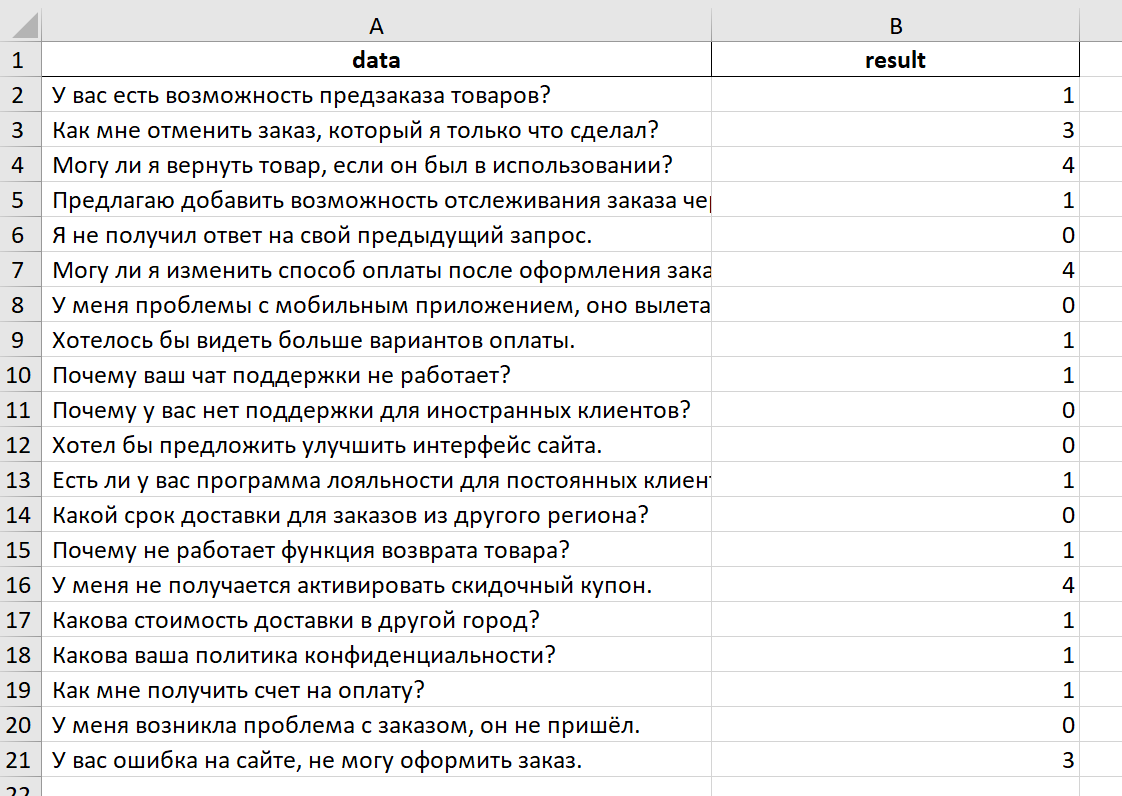
Результат
Лист1 - Информация о созданной модели, метрики и данные о нагрузке на систему:

Лист2 - Результат использования модели на тестовых данных:
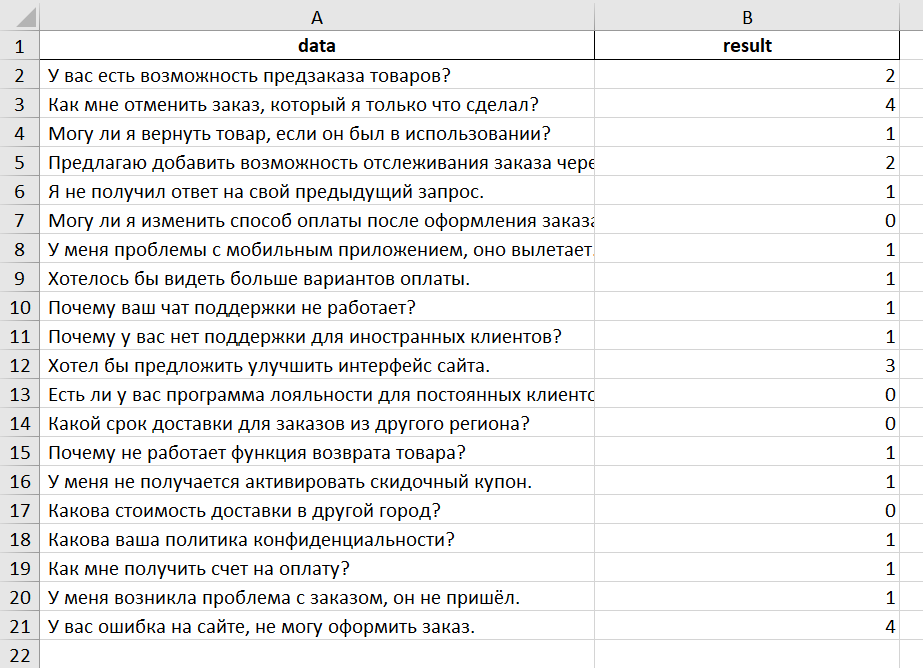
Сохраненный файл с моделью:

Лист1 - Информация о созданной модели, метрики и данные о нагрузке на систему:

Лист2 - Результат использования модели на тестовых данных:
Содержимое файла info_model.json
{ "task_id": "ab2ea865-24f6-405e-9c2f-e94135de483f", "type": "text_clustering", "model": "KMeans(n_clusters=5), TfidfVectorizer(ngram_range=(2, 3))", "metrics": [ { "metric_value": 0.03773186728358269, "metric_name": "Коэффициент сходства объектов внутри кластера" } ], "cpu_usage": { "cpu_percent": 0.4368686868686869, "ram_MB": 418.90511807528407 }, "time": 0.14055442810058594}